Daniel Brunsdon
Product + DevRel + Growth
Twitter Developer Documentation
2019 — 2022 · Information architecture & DevRel
Led the end-to-end redesign of Twitter's developer documentation serving 5.9M annual users. Unified fragmented content across three API tiers, drove a 14% lift in developer satisfaction and cut authorship time by 40%.
Context
Twitter's developer platform had grown organically over a decade. By 2019, documentation was fragmented across three separate API product lines — Standard, Premium, and Enterprise — each with its own structure, terminology, and content gaps. Content types had drifted from their original purpose: guides had become catch-alls for operator lists and feature descriptions, tutorials overlapped with guides, and FAQs were bolted onto every endpoint section. Developers couldn't find what they needed, onboarding was confusing, and internal teams were duplicating effort across a tabbed navigation system that hid child pages and offered no clear learning path.
I was brought on to fix the information architecture and rebuild the docs from the ground up — starting with the low-level sitemap (everything under the endpoint level) and working up to the high-level organization across all Twitter APIs.

The problem in detail
The existing docs had six content types applied inconsistently across endpoints, tiers, and even non-endpoint concepts like Authentication and Developer Tools:
- Overview pages tried to do too much — auth methods, parameters, tier comparisons, use cases, and constraints all on one page
- Guides vs. Tutorials was a distinction that confused developers and the team alike. Guides had become a dumping ground for code libraries, operator lists, and product timelines. Tutorials included onboarding videos and API hierarchy descriptions
- FAQs were scattered across endpoint docs with no clear ownership or maintenance path
- API Reference Index was a heavily-trafficked page (592K visits in Q1 2020 alone) that was a disorganized, incomplete list of links — Labs endpoints weren't even included
Traffic data told the story: Overview pages drew 783K visits (19% of all traffic), API Reference drew 592K (14%), but Quick Starts — the "Hello World" entry point — got just 37K (0.9%). Developers were landing on high-level pages and bouncing before they could get started.

What I did
Designed a new content type framework that gave every endpoint a consistent, progressive structure:
- Introduction — Brief description of the endpoint, what data to expect, how it's delivered. Links to use cases, quick start, integration guides, and code snippets. Replaced the bloated Overview pages
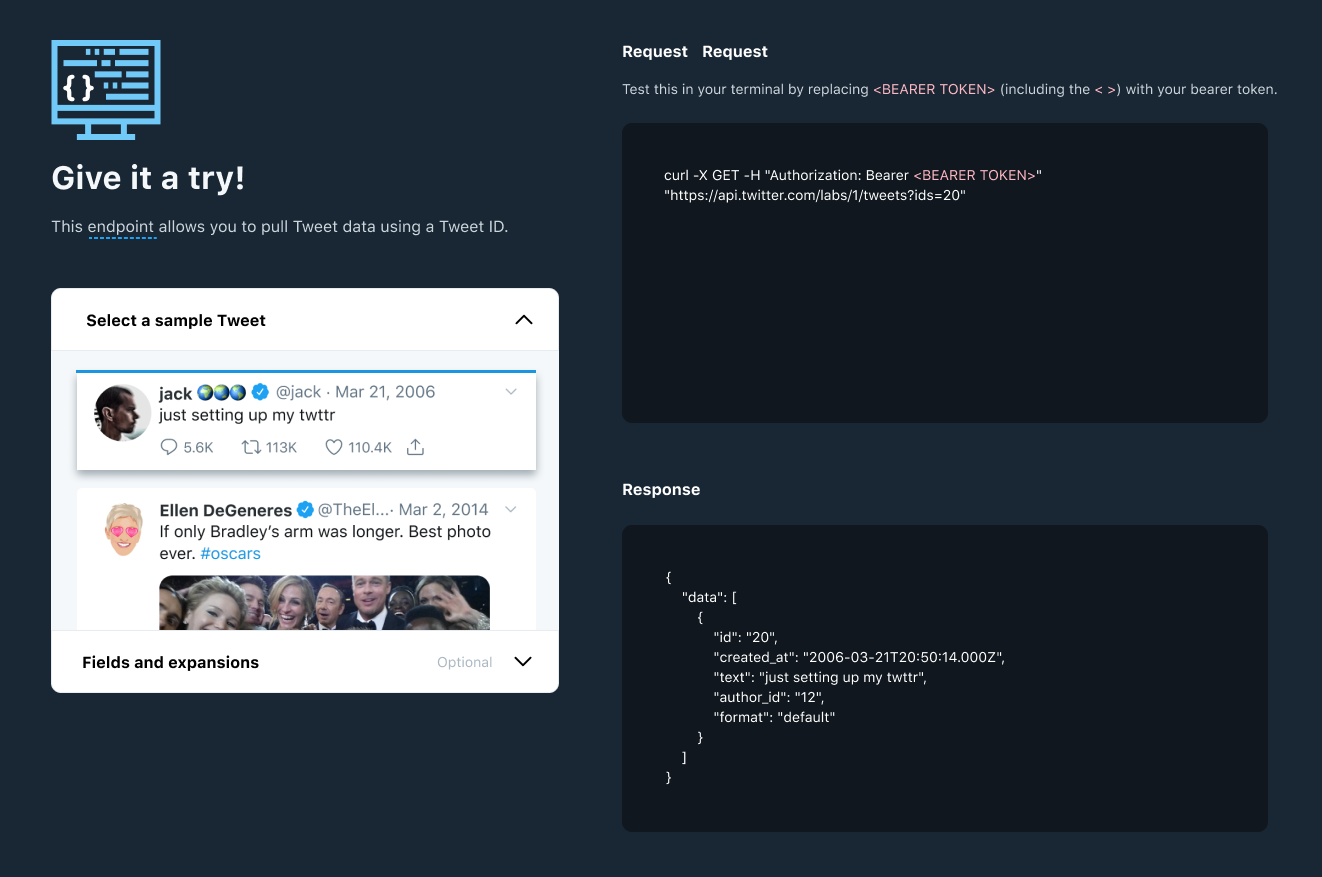
- Quick Start — Single page per endpoint section. Prerequisites, step-by-step cURL request in Postman, then links to SDKs and code snippets as next steps
- Integrate — How-to guides framed around real tasks: "How to build a rule," "How to handle disconnections," "How to recover data." Concepts like operators were embedded within guides rather than listed as standalone pages
- Migrate — Similarities and differences between v1.1 and v2, replacing the loaded "Migration" term with "Comparison" for endpoints that weren't being retired
- API Reference — Standardized on the Labs template with code snippets in all supported languages
Killed FAQs as a content type. Replaced them with contextual callouts — the same information, surfaced where developers actually encounter the confusion, not buried in a separate page.
Built content templates that standardized how any team member writes endpoint documentation. This was the key to scaling: authorship time dropped 40% and new contributor onboarding dropped 75% because the templates encoded all the structural decisions upfront.
Redesigned the high-level information architecture to organize docs around APIs (Twitter API, Ads API, Twitter for Websites, Developer Labs) rather than the legacy product-noun structure. Endpoints were grouped by consumer-facing resources with clear rules for edge cases — dependent endpoints grouped by use case (e.g., Filter Stream + Rules), related endpoints grouped by similarity (e.g., Search Tweets recent + Full-Archive Search).
Proposed the single-page anchor-link model as a future navigation pattern — replacing the fragmented tab/chapter system with a long-form page per endpoint that suggests a natural reading order and eliminates duplicative content across tabs. Benchmarked against Stripe, Twilio, Pinterest, and Google's API doc patterns.
Impact
- 5.9M developers served annually across 3 API tiers
- 14% increase in customer satisfaction scores
- 40% reduction in documentation authorship time
- 75% reduction in onboarding time for new doc contributors
- Set an IA model that other teams at Twitter adopted for their own documentation
Takeaway
Documentation is infrastructure. The hard part isn't writing — it's designing systems that scale across teams, tiers, and thousands of endpoints without drifting into inconsistency. Content types need clear boundaries. Navigation needs to match how developers actually learn. And the best IA decision I made was building templates that encoded the architecture into the authorship process itself, so it held up long after I stopped reviewing every page.
This project shaped how I think about information systems — whether it's developer docs, agent memory architecture, or CRM data models, the same principles apply: progressive disclosure, consistent taxonomy, and structure that survives contact with other contributors.